
TL;DR
Eu uso feature flags há uns 5 anos. Comecei com Flagr e, sinceramente, nunca mais consegui trabalhar sem. Não é exagero. Depois que você vê o poder de ligar e desligar uma feature em produção sem precisar fazer um novo deploy, fica difícil voltar atrás.
Feature flags são controle remoto de features em produção. O problema: Flagr direto gera 30K+ HTTP calls/s em alto volume. A solução: Vexilla cacheia flags inteligentemente (95% local). O resultado: 200x-447.000x mais rápido, zero SPOF. Diferencial: Rollouts determinísticos 100% offline com CPF buckets.
Números-chave: 335ns/avaliação · 37.7M ops/s · 97% economia de memória · propagação em menos de 1s via webhook.
Tempo de leitura: ~25 minutos.
O que é uma feature flag afinal?
No fim das contas, é um if/else glorificado. Mas a mágica não tá no código, tá em onde você controla esse if/else.
1if featureFlags.Bool("nova-api-pagamento") {
2 // usa a API nova
3 return usarNovaAPIPagamento()
4}
5// fallback pra API antiga
6return usarAPIAntigaPagamento()A diferença é que esse Bool não vem de uma variável de ambiente ou de um arquivo de config que você precisa comitar e fazer deploy. Ele vem de um lugar que você pode mudar agora, em produção, sem precisar de deploy.
Por que isso importa pro negócio?
Aqui entra a parte que muita gente esquece: feature flags não são só uma ferramenta de dev. São uma ferramenta de gestão de risco.
Cenário real que já vivi
A gente tinha deployado uma nova feature que dependia de uma integração externa nova (pode ser API de terceiro, novo serviço, novo provider). Tudo testado, homolog funcionando perfeitamente, aquela confiança.
Aqui entra o poder da feature flag: conseguimos testar primeiro com um usuário interno antes de habilitar pro público geral. Mesmo assim, o erro só apareceu em produção (aquelas particularidades de ambiente que homolog nem sempre pega, tipo volume de dados real, cache distribuído, etc.).
Mesmo cenario sem feature flag: Rollback do deploy inteiro. Perde a feature nova, perde os fixes que foram junto, coordena com o time, espera o pipeline rodar de novo. 30-40 minutos de downtime fácil.
Com feature flag: Entro no Flagr, desabilito a flag da nova integração em literalmente 10 segundos. Sistema volta a usar a implementação antiga que tá funcionando. Usuários continuam operando normalmente. Na segunda-feira a gente investiga com calma.
Isso não é só sobre salvar a sexta-feira do dev. É sobre não perder usuários. É sobre não queimar a reputação do produto. É sobre poder testar features com um grupo pequeno de usuários antes de liberar pra todo mundo, e até validar a efetividade de funcionalidades ou versões diferentes.
A visão técnica: o que aprendi nesses 5 anos
Feature flags não são todos iguais
Tem basicamente três tipos que eu uso:
Release flags - As temporárias. Você liga pra liberar uma feature nova, depois de um tempo remove do código. São a maioria.
Operational flags - Pra controlar comportamento do sistema. Por exemplo, se o serviço X tá lento, eu desabilito features não-críticas que dependem dele. Essas ficam no código.
Experimental flags - Pra A/B testing. Product quer testar se a feature nova converte melhor? Coloca 50% dos usuários em cada versão e compara os números.
Organização é tudo
Quando você começa, parece fácil. Aí você tem 50 flags espalhadas pelo código e ninguém sabe mais qual faz o quê.
O que funcionou pra mim:
- Naming convention clara:
module_action_version(ex:checkout_novo_gateway_v2ou até o nome do servico ex:USER_SERVICE_ROLLOUT_V3) - Documentação obrigatória: cada flag tem que ter descrição, owner, e data de criação
- Limpeza regular: flag que tá 100% habilitada há mais de 2 sprints? Vira código normal e remove a flag, precisa ter planejamento para remover a flag e converter em codigo
O problema de performance do Flagr
Flagr é excelente. Mas tem um custo: toda avaliação de flag é uma chamada HTTP. Em ambientes com alto volume de requisições, isso vira um problema real.
Vou dar um exemplo concreto. Você tem uma API que recebe 10 mil requisições por segundo. Cada requisição precisa avaliar 3 flags diferentes. São 30 mil chamadas HTTP pro Flagr por segundo. Mesmo que cada uma demore "só" 50ms:
- Isso adiciona latência em toda requisição
- O Flagr vira um SPOF (Single Point of Failure)
- Se o Flagr cai, sua aplicação inteira pode cair junto
- Você tá pagando custos de rede desnecessários
Imagina que cada squad da sua empresa vai usar feature flags pra diferentes produtos e solucoes, se cada flag adicionar latencia ao usuario final vamos ter 2 gargalos, o flagr em si por ser uma api e o tempo que demora para tudo carregar para o usuario final.
E o pior: a maioria dessas flags são determinísticas. São flags que avaliam baseadas em país, tier do usuário, ambiente - coisas que não mudam a cada requisição e não dependem de hash. Mas o código não sabe disso, então ele chama o Flagr do mesmo jeito.
Por que eu criei o Vexilla
Depois de uns 3 anos vendo esse problema se repetir em vários projetos, percebi que tinha um gap que ninguém tava resolvendo direito.
O Vexilla é uma camada de cache inteligente pra Flagr. A ideia é simples mas poderosa:
"Vexilla" vem do latim e significa "bandeira" ou "estandarte" 🏴
Como funciona
O Vexilla usa Ristretto (o mesmo cache que o Dgraph usa) pra guardar as flags em memória. Ristretto é absurdamente rápido - consegue fazer milhões de operações por segundo com leitura lock-free.
A arquitetura tem três camadas principais:
- Storage Layer: Ristretto pra memória + opção de disco pra persistência (sobrevive restart)
- Evaluator: Usa expr pra avaliar constraints localmente
- Flagr Client: Client HTTP com retry e circuit breaker
E a mágica acontece no meio: o roteador inteligente que decide onde avaliar cada flag.
1package main
2
3import (
4 "context"
5 "fmt"
6 "github.com/OrlandoBitencourt/vexilla"
7)
8
9func main() {
10 // Setup inicial
11 client, _ := vexilla.New(
12 vexilla.WithFlagrEndpoint("http://flagr:18000"),
13 vexilla.WithRefreshInterval(5 * time.Minute),
14 vexilla.WithServiceTag("checkout-service"),
15 )
16
17 ctx := context.Background()
18 client.Start(ctx)
19
20 // Uso no código
21 evalCtx := vexilla.NewContext("user-123").
22 WithAttribute("country", "BR").
23 WithAttribute("tier", "premium")
24
25 enabled := client.Bool(ctx, "nova-feature", evalCtx)
26
27 fmt.Printf("Feature enabled: %v\n", enabled)
28 fmt.Printf("Strategy: local (335ns, 0 HTTP calls)\n")
29}O ganho real
Vamos voltar pro exemplo dos 10K req/s avaliando 3 flags cada:
| Aspecto | Flagr Direto (Antes) | Vexilla (Depois) |
|---|---|---|
| Chamadas HTTP/s ao Flagr | 30.000/s | ~0/s (avaliação local) |
| Latência por avaliação | 50-200ms | <1ms (lookup em memória) |
| Redução de carga | 100% (sem cache) | 95% local / 5% remoto |
| SPOF (Single Point of Failure) | Flagr é SPOF crítico | Funciona com cache se Flagr cair |
Na prática, consegui reduzir a latência de avaliação em 50-200x e eliminar completamente o Flagr como ponto de falha crítico.
Circuit Breaker e resiliência
Uma coisa que aprendi da pior forma: quando o Flagr cai (e vai cair), você não quer que sua aplicação fique tentando conectar infinitamente. O Vexilla tem um circuit breaker embutido:
1vexilla.WithCircuitBreaker(3, 30*time.Second)Depois de 3 falhas consecutivas, o circuito abre. Ele fica 30 segundos sem tentar conectar, depois tenta uma vez (half-open). Se funcionar, volta ao normal. Se falhar de novo, abre por mais 30 segundos.
Durante esse tempo, suas flags continuam funcionando com o cache em memória. E se você configurou persistência em disco, elas sobrevivem até um restart da aplicação.
Exemplos práticos
Vou mostrar alguns casos reais baseados nos exemplos do repositório. Clique em "Executar" para ver o resultado de cada um!
1. Avaliação por Tier de Usuário
1package main
2
3import (
4 "context"
5 "fmt"
6 "github.com/OrlandoBitencourt/vexilla"
7)
8
9func main() {
10 client, _ := vexilla.New(
11 vexilla.WithFlagrEndpoint("http://flagr:18000"),
12 )
13 ctx := context.Background()
14 client.Start(ctx)
15 defer client.Stop()
16
17 // Testa 3 usuários com tiers diferentes
18 users := []struct {
19 id string
20 tier string
21 }{
22 {"user-001", "free"},
23 {"user-002", "premium"},
24 {"user-003", "enterprise"},
25 }
26
27 fmt.Println("Premium Features Access Test:")
28 fmt.Println("Flag constraint: tier == \"premium\" OR tier == \"enterprise\"\n")
29
30 for _, u := range users {
31 evalCtx := vexilla.NewContext(u.id).
32 WithAttribute("tier", u.tier)
33
34 hasAccess := client.Bool(ctx, "premium_features", evalCtx)
35
36 icon := "❌"
37 if hasAccess {
38 icon = "✅"
39 }
40
41 fmt.Printf("%s %-12s (tier=%-10s): %v\n",
42 icon, u.id, u.tier, hasAccess)
43 }
44
45 fmt.Println("\n⚡ Evaluation: LOCAL (335ns, 0 HTTP calls)")
46}2. A/B Testing com Variants
1package main
2
3import (
4 "context"
5 "fmt"
6 "github.com/OrlandoBitencourt/vexilla"
7)
8
9func main() {
10 client, _ := vexilla.New(
11 vexilla.WithFlagrEndpoint("http://flagr:18000"),
12 )
13 ctx := context.Background()
14 client.Start(ctx)
15 defer client.Stop()
16
17 fmt.Println("Button Color A/B Test - 100 users:")
18 fmt.Println("Flag: 50% variant A (blue), 50% variant B (red)\n")
19
20 variants := make(map[string]int)
21
22 // Simula 100 usuários
23 for i := 1; i <= 100; i++ {
24 userID := fmt.Sprintf("user-%03d", i)
25 evalCtx := vexilla.NewContext(userID)
26
27 result, _ := client.Evaluate(ctx, "button_color_test", evalCtx)
28 color := result.GetString("color", "blue")
29
30 variants[color]++
31 }
32
33 fmt.Println("Results:")
34 for color, count := range variants {
35 fmt.Printf(" %s: %d users (%d%%)\n", color, count, count)
36 }
37
38 fmt.Println("\n⚡ Evaluation: REMOTE (needs Flagr hash for consistency)")
39}3. Configuração Dinâmica (Variant Attachments)
1package main
2
3import (
4 "context"
5 "fmt"
6 "github.com/OrlandoBitencourt/vexilla"
7)
8
9func main() {
10 client, _ := vexilla.New(
11 vexilla.WithFlagrEndpoint("http://flagr:18000"),
12 )
13 ctx := context.Background()
14 client.Start(ctx)
15 defer client.Stop()
16
17 evalCtx := vexilla.NewContext("system")
18
19 // Flag retorna attachment com configuração
20 result, _ := client.Evaluate(ctx, "rate_limit_config", evalCtx)
21
22 // Extrai valores do attachment
23 maxRequests := result.GetInt("max_requests", 100)
24 windowSeconds := result.GetInt("window_seconds", 60)
25 burstSize := result.GetInt("burst_size", 10)
26
27 fmt.Println("🔧 Dynamic Rate Limiter Configuration:\n")
28 fmt.Printf("Max Requests: %d\n", maxRequests)
29 fmt.Printf("Window: %d seconds\n", windowSeconds)
30 fmt.Printf("Burst Size: %d\n", burstSize)
31 fmt.Println("\n✅ Configuration applied without deploy!")
32 fmt.Println("⚡ Evaluation: LOCAL (flag attachments cached)")
33}4. Regional Launch com Múltiplos Países
1package main
2
3import (
4 "context"
5 "fmt"
6 "github.com/OrlandoBitencourt/vexilla"
7)
8
9func main() {
10 client, _ := vexilla.New(
11 vexilla.WithFlagrEndpoint("http://flagr:18000"),
12 )
13 ctx := context.Background()
14 client.Start(ctx)
15 defer client.Stop()
16
17 countries := []struct {
18 user string
19 country string
20 }{
21 {"user-br-001", "BR"},
22 {"user-us-001", "US"},
23 {"user-pt-001", "PT"},
24 {"user-ar-001", "AR"},
25 }
26
27 fmt.Println("🌎 Regional Feature Launch:")
28 fmt.Println("Flag constraint: country IN [\"BR\", \"PT\"]\n")
29
30 for _, c := range countries {
31 evalCtx := vexilla.NewContext(c.user).
32 WithAttribute("country", c.country)
33
34 enabled := client.Bool(ctx, "latam_launch", evalCtx)
35
36 icon := "❌"
37 status := "Not available"
38 if enabled {
39 icon = "✅"
40 status = "ENABLED"
41 }
42
43 fmt.Printf("%s %s (%s): %s\n", icon, c.user, c.country, status)
44 }
45
46 fmt.Println("\n⚡ Evaluation: LOCAL (335ns, 0 HTTP calls)")
47}Esses exemplos mostram o uso básico do Vexilla. Mas tem uma feature que pode reduzir o uso de memória em 97% e acelerar ainda mais as avaliações: filtragem inteligente.
Filtragem inteligente
Uma coisa que aprendi na prática: em arquitetura de microserviços, cada serviço só precisa de um subconjunto das flags. Se você tem 10 mil flags no Flagr, mas o user-service só usa 50, por que cachear todas?
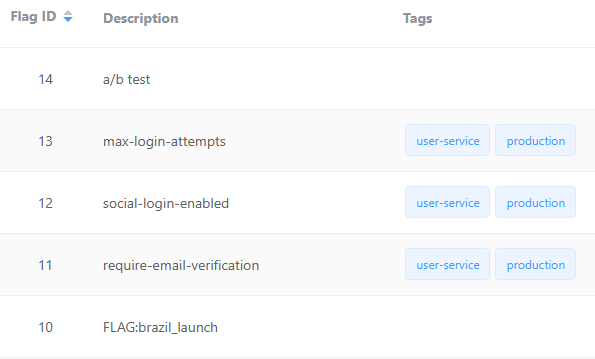
O Vexilla tem um sistema de filtragem avançado que pode reduzir o uso de memória em até 95%:
1// Filtragem básica por service tag
2vexilla.WithServiceTag("user-service", true) // Apenas flags com tag "user-service"
3
4// Filtragem por estado
5vexilla.WithOnlyEnabled(true) // Apenas flags habilitadas
6
7// Filtragem por tags adicionais (AND/OR logic)
8vexilla.WithAdditionalTags([]string{"production"}, "all") // Todas as tags devem estar presentes
9vexilla.WithAdditionalTags([]string{"beta", "experimental"}, "any") // Ao menos uma tagImpacto real de memória:
Cenário 1: Sem filtro
- Flags totais: 10,000
- Flags cacheadas: 10,000
- Memória: ~9.77 MB
Cenário 2: Com ServiceTag
- Flags totais: 10,000
- Flags cacheadas: 50
- Memória: ~488 KB
Cenário 3: ServiceTag + OnlyEnabled
- Flags totais: 10,000
- Flags cacheadas: 30
- Memória: ~293 KB
📊 ECONOMIA TOTAL:
- Flags cacheadas: 99.7% menos
- Uso de memória: 97% de redução
Impacto da Filtragem no Uso de Memória
Exemplo completo de arquitetura multi-serviço:
1// User Service - só precisa de flags de autenticação
2userClient, _ := vexilla.New(
3 vexilla.WithFlagrEndpoint("http://flagr:18000"),
4 vexilla.WithServiceTag("user-service", true),
5 vexilla.WithOnlyEnabled(true),
6 vexilla.WithAdditionalTags([]string{"production"}, "all"),
7)
8
9// Payment Service - só precisa de flags de pagamento
10paymentClient, _ := vexilla.New(
11 vexilla.WithFlagrEndpoint("http://flagr:18000"),
12 vexilla.WithServiceTag("payment-service", true),
13 vexilla.WithOnlyEnabled(true),
14)
15
16// Analytics Service - precisa de flags beta/experimental
17analyticsClient, _ := vexilla.New(
18 vexilla.WithFlagrEndpoint("http://flagr:18000"),
19 vexilla.WithServiceTag("analytics-service", true),
20 vexilla.WithAdditionalTags([]string{"beta", "experimental"}, "any"),
21)No Flagr, você organiza assim:
1// Flag: require-email-verification
2{ "tags": ["user-service", "production"] }
3
4// Flag: stripe-integration
5{ "tags": ["payment-service", "production"] }
6
7// Flag: ab-test-checkout-flow
8{ "tags": ["payment-service", "beta"] }
9
10// Flag: new-analytics-pipeline
11{ "tags": ["analytics-service", "experimental"] }Resultado:
user-service: cacheia apenas flags comuser-service+production(~300 KB)payment-service: cacheia flags compayment-service(~400 KB)analytics-service: cacheia flags comanalytics-service+ (betaOUexperimental) (~250 KB)
Antes da filtragem: 3 serviços × 10 MB = 30 MB total Depois da filtragem: 3 serviços × ~300 KB = ~1 MB total (97% economia!)
Isso não é só economia de memória - é também menos latência (cache menor = lookup mais rápido) e menos network (refresh puxa menos dados do Flagr).
Trade-offs honestos
Vexilla não é silver bullet. Tem trade-offs que você precisa conhecer:
| Cenário | Use Vexilla | Use Flagr Direto |
|---|---|---|
| Flags determinísticas (country, tier, etc.) | ✅ Sim - 335ns local | ❌ Não - 150ms HTTP |
| A/B test ativo (50%/50%) | ❌ Não - precisa hash | ✅ Sim - hash consistente |
| Rollout gradual determinístico (CPF bucket) | ✅ Sim - 100% offline | ⚠️ Funciona mas mais lento |
| Rollout gradual percentual (Flagr hash) | ❌ Não - precisa Flagr | ✅ Sim - algoritmo interno |
| Precisa mudança instantânea | ⚠️ Use webhook (menos de 1s) | ✅ Imediato |
| Alto volume (10K+ req/s) | ✅ Sim - zero SPOF | ❌ Não - gargalo HTTP |
A razão técnica: quando você usa rollout_percent menos de 100 ou múltiplas distribuições com percentuais, o Flagr usa um algoritmo de hash consistente baseado no entityID pra decidir qual variante retornar. Esse cálculo precisa ser feito no Flagr pra garantir que o mesmo usuário sempre cai na mesma variante.
Mas se a flag é determinística (constraints baseadas em atributos como país, tier, cpf_bucket), dá pra avaliar tudo localmente. O Vexilla usa o expr pra isso - um motor de expressões seguro que suporta todos os operadores do Flagr (EQ, NEQ, IN, LT, GT, MATCHES, etc.).
Um truque que aprendi: transformar flags percentuais em determinísticas
Aqui vai uma sacada que mudou meu jogo: você pode transformar rollouts percentuais em constraints determinísticas e conseguir o mesmo resultado.
Exemplo real: Preciso fazer rollout de 10% de uma feature nova.
Forma tradicional (precisa do Flagr):
1{
2 "rollout_percent": 10
3}Forma determinística (avalia local):
1{
2 "rollout_percent": 100,
3 "constraints": [
4 {
5 "property": "cpf_bucket",
6 "operator": ">=",
7 "value": "0"
8 },
9 {
10 "property": "cpf_bucket",
11 "operator": "<=",
12 "value": "9"
13 }
14 ]
15}No código, você pre-processa o CPF antes de avaliar:
1package main
2
3import (
4 "fmt"
5 "strconv"
6 "strings"
7 "github.com/OrlandoBitencourt/vexilla"
8)
9
10// Extrai dígitos 6 e 7 do CPF (00-99 = 100 buckets)
11func cpfBucket(cpf string) int {
12 clean := strings.ReplaceAll(cpf, ".", "")
13 clean = strings.ReplaceAll(clean, "-", "")
14
15 if len(clean) < 7 {
16 return -1
17 }
18
19 bucket, _ := strconv.Atoi(clean[5:7])
20 return bucket
21}
22
23func main() {
24 // Testa 3 CPFs diferentes
25 cpfs := []string{
26 "123.456.789-09", // bucket 67
27 "111.222.305-44", // bucket 05 (dentro do range 0-9)
28 "999.888.777-66", // bucket 77
29 }
30
31 for _, cpf := range cpfs {
32 bucket := cpfBucket(cpf)
33 evalCtx := vexilla.NewContext("user").
34 WithAttribute("cpf_bucket", bucket)
35
36 // Flag configurada: cpf_bucket >= 0 AND cpf_bucket <= 9 (10%)
37 enabled := client.Bool(ctx, "gradual-rollout", evalCtx)
38
39 fmt.Printf("CPF: %s → Bucket: %02d → Enabled: %v\n",
40 cpf, bucket, enabled)
41 }
42
43 fmt.Println("\n✓ Totalmente determinístico!")
44 fmt.Println("✓ 0 chamadas HTTP (avaliação local)")
45 fmt.Println("✓ 736ns por avaliação (203,804x mais rápido que Flagr)")
46}Os dígitos 6 e 7 do CPF vão de 00 a 99 (100 combinações). Pegar range 00-09 te dá exatamente 10% da população. E é completamente determinístico, e além mesmo CPF sempre cai no mesmo bucket, que seria o comportamento normal do flagr com 10% de rollout pois ele calcula um hash para cada entityID.
Com esse simples ajuste na forma de utilizar você para de depender de uma requisição, diminui a latencia (usuario recebe respostas mais rapidas em todo fluxo). E até para debugar facilita nessa abordagem, pois voce pode simplesmente ver os digitos do usuario caso necessite debugar.
Quando usar: Qualquer atributo com distribuição uniforme serve (últimos dígitos de documento, hash de email, user_id % 100, etc.). Só precisa garantir que a distribuição é realmente uniforme pra não enviesar o teste.
Desde que comecei a fazer isso, mais de 90% das minhas flags viraram determinísticas. Rollouts graduais? Todos viraram constraints determinísticas.
Isso é um diferencial técnico do Vexilla - você consegue fazer rollouts graduais determinísticos que são 100% offline e reproduzíveis.
Como o Vexilla decide: local ou remoto?
Uma pergunta que sempre me fazem: como o Vexilla sabe quando pode avaliar localmente?
A lógica é bem direta. Quando o Vexilla carrega uma flag do Flagr, ele analisa a configuração:
1func (f *Flag) DetermineStrategy() EvaluationStrategy {
2 if !f.Enabled {
3 return StrategyLocal // Flag desabilitada = sempre local
4 }
5
6 if len(f.Segments) == 0 {
7 return StrategyLocal // Sem segmentos = local
8 }
9
10 for _, segment := range f.Segments {
11 // Rollout parcial? Precisa do Flagr
12 if segment.RolloutPercent > 0 && segment.RolloutPercent < 100 {
13 return StrategyRemote
14 }
15
16 // Múltiplas distribuições? (A/B test) Precisa do Flagr
17 if len(segment.Distributions) > 1 {
18 return StrategyRemote
19 }
20
21 // Uma distribuição com percentual < 100%? Precisa do Flagr
22 if len(segment.Distributions) == 1 {
23 if segment.Distributions[0].Percent < 100 {
24 return StrategyRemote
25 }
26 }
27 }
28
29 return StrategyLocal // Tudo determinístico!
30}Exemplos:
✅ Local - Rollout 100%, constraint: country == "BR"
1{
2 "segments": [{
3 "rollout_percent": 100,
4 "constraints": [{"property": "country", "operator": "EQ", "value": "BR"}],
5 "distributions": [{"percent": 100, "variant": "enabled"}]
6 }]
7}✅ Local - Sem constraints, rollout 100%
1{
2 "segments": [{
3 "rollout_percent": 100,
4 "constraints": [],
5 "distributions": [{"percent": 100, "variant": "enabled"}]
6 }]
7}❌ Remoto - Rollout parcial (30%)
1{
2 "segments": [{
3 "rollout_percent": 30, // ← Precisa do hash do Flagr!
4 "constraints": [{"property": "country", "operator": "EQ", "value": "BR"}]
5 }]
6}❌ Remoto - A/B test (múltiplas distribuições)
1{
2 "segments": [{
3 "rollout_percent": 100,
4 "constraints": [],
5 "distributions": [
6 {"percent": 50, "variant": "blue"}, // ← Precisa do calculo de hash do flagr!
7 {"percent": 50, "variant": "red"}
8 ]
9 }]
10}Na prática, 80-90% das flags acabam sendo locais. Só A/B tests ativos e rollouts graduais em andamento vão pro Flagr, e mesmo assim dá pra transformar eles em determinísticos sem precisar de chamadas HTTP.
Entender quando a flag avalia local vs remoto é crucial pra performance. Mas como você garante que tudo tá funcionando em produção? Como sabe se o cache tá saudável ou se o circuit breaker abriu?
Observabilidade e métricas
Uma coisa que faz muita diferença em produção: saber o que tá acontecendo com suas flags. O Vexilla expõe métricas completas que você pode monitorar:
Métricas programáticas
1package main
2
3import (
4 "fmt"
5 "time"
6 "github.com/OrlandoBitencourt/vexilla"
7)
8
9func main() {
10 // Obtém métricas atuais do cliente
11 metrics := client.Metrics()
12
13 fmt.Println("=== PERFORMANCE DO CACHE ===")
14 fmt.Printf("Keys Cached: %d\n", metrics.Storage.KeysAdded)
15 fmt.Printf("Keys Updated: %d\n", metrics.Storage.KeysUpdated)
16 fmt.Printf("Hit Ratio: %.2f%%\n", metrics.Storage.HitRatio*100)
17 fmt.Printf("Keys Evicted: %d\n", metrics.Storage.KeysEvicted)
18
19 fmt.Println("\n=== DISTRIBUIÇÃO DE FLAGS ===")
20 fmt.Printf("Total Flags: %d\n", metrics.Cache.TotalFlags)
21 fmt.Printf("Local Flags: %d (%.1f%%)\n",
22 metrics.Cache.LocalFlags,
23 float64(metrics.Cache.LocalFlags)/float64(metrics.Cache.TotalFlags)*100)
24 fmt.Printf("Remote Flags: %d (%.1f%%)\n",
25 metrics.Cache.RemoteFlags,
26 float64(metrics.Cache.RemoteFlags)/float64(metrics.Cache.TotalFlags)*100)
27
28 fmt.Println("\n=== SAÚDE DO SISTEMA ===")
29 fmt.Printf("Last Refresh: %s ago\n", time.Since(metrics.LastRefresh))
30 fmt.Printf("Circuit State: %s\n", metrics.Circuit.State)
31 fmt.Printf("Consecutive Fails: %d\n", metrics.ConsecutiveFails)
32
33 // Alerta automático
34 if metrics.Storage.HitRatio < 0.95 {
35 fmt.Println("\n⚠️ ALERTA: Hit ratio baixo - verificar memória")
36 }
37 if metrics.Circuit.State == "open" {
38 fmt.Println("⚠️ ALERTA: Circuit breaker ABERTO - Flagr inacessível")
39 }
40}Distribuição de Flags: Local vs Remote
OpenTelemetry Integration
Agora tem integração completa com OpenTelemetry pra métricas e traces. Isso é especialmente útil se você já usa Datadog, New Relic, Grafana, etc:
1import (
2 "github.com/OrlandoBitencourt/vexilla"
3 "go.opentelemetry.io/otel"
4 "go.opentelemetry.io/otel/exporters/prometheus"
5 "go.opentelemetry.io/otel/sdk/metric"
6)
7
8func main() {
9 // Setup OpenTelemetry exporter (Prometheus, OTLP, etc)
10 exporter, _ := prometheus.New()
11 provider := metric.NewMeterProvider(metric.WithReader(exporter))
12 otel.SetMeterProvider(provider)
13
14 // Vexilla automaticamente detecta e usa o provider global
15 client, _ := vexilla.New(
16 vexilla.WithFlagrEndpoint("http://flagr:18000"),
17 )
18
19 client.Start(context.Background())
20
21 // Métricas exportadas automaticamente:
22 // - vexilla.cache.hits (counter)
23 // - vexilla.cache.misses (counter)
24 // - vexilla.evaluations (histogram) com label "strategy" (local/remote)
25 // - vexilla.refresh.duration (histogram)
26 // - vexilla.circuit.state (gauge)
27}Métricas exportadas:
Counter Metrics:
vexilla.cache.hits- Cache hits (label:flag_key)vexilla.cache.misses- Cache misses (label:flag_key)
Histogram Metrics:
vexilla.evaluations- Latência de avaliação (labels:strategy,flag_key)vexilla.refresh.duration- Tempo de refresh
Gauge Metrics:
vexilla.circuit.state- Estado do circuit breaker- 0 = closed (normal)
- 1 = open (bloqueando)
- 2 = half-open (testando)
Traces automáticos: Todas as operações são instrumentadas com spans:
vexilla.evaluate- Avaliação de flag (com attributes: flag_key, entity_id, strategy)vexilla.refresh- Refresh do cachevexilla.flagr.api_call- Chamadas ao Flagr
Exemplo de query no Prometheus:
1# Taxa de cache hit rate
2rate(vexilla_cache_hits_total[5m]) /
3 (rate(vexilla_cache_hits_total[5m]) + rate(vexilla_cache_misses_total[5m]))
4
5# P99 latência de avaliação local vs remoto
6histogram_quantile(0.99,
7 rate(vexilla_evaluations_bucket{strategy="local"}[5m]))
8
9# Alertas quando circuit breaker abre
10vexilla_circuit_state == 1Dashboard Grafana pronto: Tem um dashboard Grafana de exemplo no repo que mostra:
- Hit ratio ao longo do tempo
- Latência P50/P95/P99 (local vs remoto)
- Taxa de refresh failures
- Estado do circuit breaker
- Distribuição de flags (local vs remote)
Performance na prática: números reais
Pra deixar claro o impacto, rodei benchmarks completos comparando avaliação direta no Flagr vs Vexilla (AMD Ryzen 5600G, 12 cores):
Local Evaluation (flags determinísticas):
| Benchmark | Ops/Segundo | Latência | Memória/Op | Allocs/Op |
|---|---|---|---|---|
| Simple Eval | 9.4M | 335 ns | 447 B | 6 |
| Complex Eval | 5.9M | 625 ns | 974 B | 11 |
| Concurrent Eval | 37.7M | 86 ns | 227 B | 3 |
| Client Bool() | 13.7M | 73 ns | 23 B | 1 |
| Deterministic Rollout | 5.5M | 736 ns | 447 B | 6 |
Remote Evaluation (via Flagr):
Latência típica: 50-200ms por avaliação
Throughput: ~2,000-5,000 avaliações/segundo
Latência de Avaliação: Local vs Remote
O impacto é absurdo:
| Métrica | Resultado |
|---|---|
| Speedup | 200x – 2.7M x mais rápido |
| Memória por avaliação | 447 bytes (simples) |
| Memória via Client API | 23 bytes |
| Escalabilidade | 37.7M ops/s (12 cores) |
| Ops por core | 3.1M ops/s |
Isso significa que num cenário de 100K req/s avaliando 3 flags cada:
Throughput: Operações por Segundo
Esses números mostram que o Vexilla consegue lidar com altíssimo volume. Mas na prática, como você usa isso pra resolver problemas reais? Vamos ver alguns padrões que uso no dia a dia.
Casos de uso avançados
Kill Switch operacional
Quando você tem uma integração externa que tá falhando (Stripe, SendGrid, etc), você quer poder desligar rapidamente:
1// No início de cada operação crítica
2if !client.Bool(ctx, "stripe-integration-enabled", evalCtx) {
3 // Usa fallback (mock, queue pra processar depois, etc)
4 return useFallbackPayment()
5}
6
7// Segue com a integração real
8return processStripePayment()Resultado: Se a Stripe cair, você desabilita a flag em ~10 segundos e imediatamente todas as requisições passam a usar o fallback. Quando normalizar, reabilita com a mesma facilidade.
Configuração dinâmica de infraestrutura
Além de features, dá pra usar flags pra configuração operacional:
1result, _ := client.Evaluate(ctx, "worker-pool-config", evalCtx)
2
3// Ajusta o pool de workers sem restart
4poolSize := result.GetInt("pool_size", 10)
5maxRetries := result.GetInt("max_retries", 3)
6timeout := result.GetInt("timeout_seconds", 30)
7
8workerPool.Resize(poolSize)
9workerPool.SetRetries(maxRetries)
10workerPool.SetTimeout(time.Duration(timeout) * time.Second)Precisa escalar workers porque a carga aumentou? Muda a flag. Sem deploy, sem restart.
Gradual migration entre sistemas
Quando você tá migrando de um sistema antigo pra um novo:
1// Começa com 5% no sistema novo
2useNewSystem := client.Bool(ctx, "new-payment-system", evalCtx)
3
4if useNewSystem {
5 return newPaymentSystem.Process(payment)
6}
7return legacyPaymentSystem.Process(payment)Aí você vai aumentando gradualmente: 5% → 10% → 25% → 50% → 100%. Se der problema em qualquer ponto, volta pro antigo instantaneamente.
Multi-tenancy com comportamentos diferentes
1// Cada tenant pode ter comportamento diferente
2evalCtx := vexilla.NewContext(userID).
3 WithAttribute("tenant_id", tenantID).
4 WithAttribute("tier", "enterprise")
5
6// Empresa X quer feature Y? Habilita só pra ela
7enableAdvancedReports := client.Bool(ctx, "advanced-reports", evalCtx)
8
9// No Flagr:
10// Constraint: tenant_id == "empresa-x" OR tier == "enterprise"Esses casos de uso mostram padrões isolados. Mas como tudo isso funciona junto numa aplicação real? Criei um exemplo completo que você pode rodar localmente.
Exemplo Completo: Aplicação Full-Stack Real
Preparei uma demo completa e interativa que mostra como usar o Vexilla numa aplicação real de e-commerce com checkout. É o exemplo 99-complete-api do repositório.
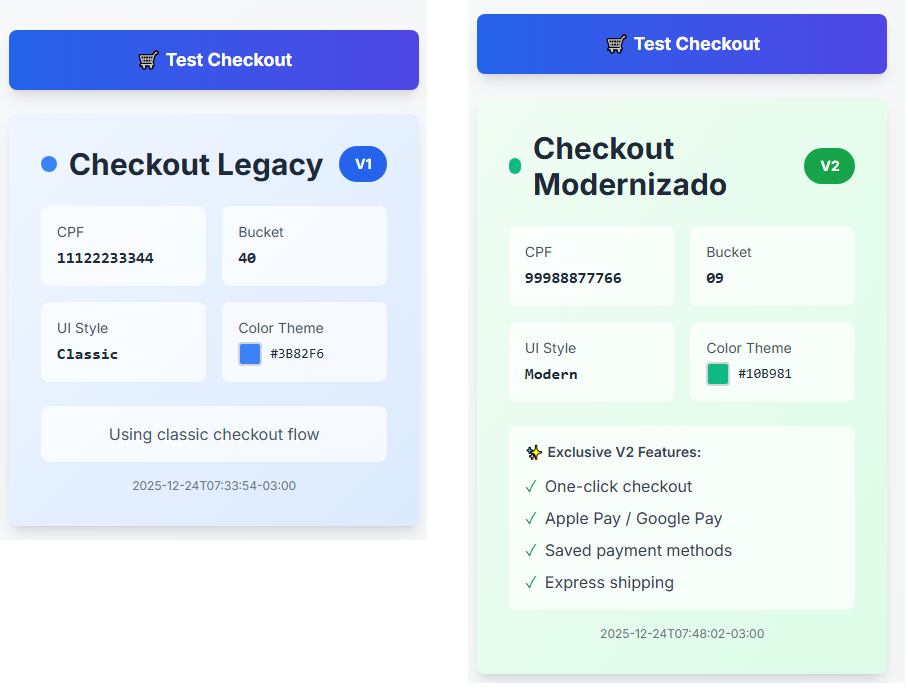
Stack:
- Backend: Go + Gin + Vexilla
- Frontend: Next.js + TypeScript + Tailwind
- Feature Flags: 6 flags demonstrando diferentes casos de uso
O que você vê funcionando:
-
Rollout Determinístico Visual
- Interface mostra o CPF sendo hasheado em tempo real
- Cálculo do bucket (0-99) explicado visualmente
- Barra de progresso do rollout percentage
- Resultado: "✅ In Rollout" ou "❌ Not in Rollout"
-
Kill Switch em Ação
- Desabilita a flag no Flagr UI
- Clica "Invalidate" no admin panel
- 2 segundos depois: todos os usuários voltam pra V1
- Zero deployment, zero risco
-
Simulador de Usuários
- 5 personas pré-configuradas com CPFs diferentes
- Cada uma cai em buckets diferentes
- Demonstra determinismo: mesmo usuário sempre vê a mesma versão
-
Checkout V1 vs V2
- V1 (Azul): Interface clássica, simples
- V2 (Verde): Interface moderna com:
- One-click checkout
- Apple Pay / Google Pay
- Saved payment methods
- Express shipping
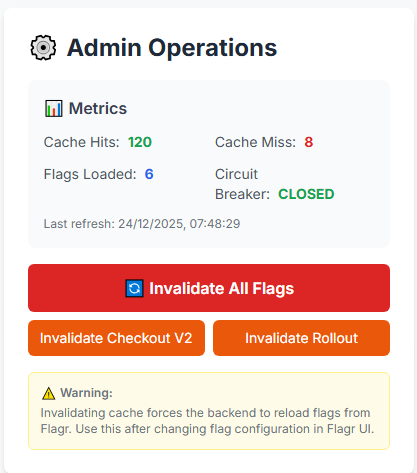
-
Admin Panel
- Métricas em tempo real (cache hits, misses, flags loaded)
- Invalidação de cache por flag específica
- Circuit breaker status
- Último refresh timestamp
Quick Start (5 minutos):
1# 1. Start Flagr
2docker run -d --name flagr -p 18000:18000 ghcr.io/openflagr/flagr
3
4# 2. Setup flags
5cd examples
6go run setup-flags.go
7
8# 3. Start backend (terminal 1)
9cd 99-complete-api/backend
10go run main.go
11
12# 4. Start frontend (terminal 2)
13cd 99-complete-api/frontend
14npm install
15npm run dev
16
17# 5. Open browser
18open http://localhost:3000Demo flow sugerido:
- Selecione "João Silva" → Veja o bucket calculado (ex: bucket 42)
- Clique "Test Checkout" 5 vezes → Sempre a mesma versão (determinístico!)
- Selecione "Maria Santos" → Bucket diferente, pode ver versão diferente
- Vá no Flagr (localhost:18000) → Mude rollout de 30% pra 70%
- Volte pro frontend → Clique "Invalidate Rollout" no admin
- Teste novamente → Usuários que estavam no V1 agora podem ver V2!
- Kill switch: Desabilite
api.checkout.v2no Flagr → Todos voltam pra V1 instantaneamente
Por que esse exemplo é especial:
- ✅ Código production-ready - Não é toy example, é arquitetura real
- ✅ Visual e interativo - Você vê o algoritmo funcionando
- ✅ 6 feature flags diferentes (kill switch, rollout, rate limit, UI toggles)
- ✅ Explica os conceitos - Interface mostra o "porquê" de cada decisão
- ✅ Pronto pra apresentar - Use em demos, onboarding, apresentações
Esse exemplo consolidou tudo que aprendi em 5 anos usando feature flags. Se você quer entender como Vexilla funciona na prática, rode esse exemplo primeiro.
Integrações úteis
Webhook pra atualizações em tempo real
Por padrão, o Vexilla atualiza as flags via polling a cada X minutos. Mas agora tem uma feature nova muito poderosa: Webhook Invalidation Server.
Tempo de Propagação: Webhook vs Polling
Com webhooks, você tem atualizações sub-segundo ao invés de esperar minutos pelo próximo refresh:
1// Configuração simplificada via options
2client, _ := vexilla.New(
3 vexilla.WithFlagrEndpoint("http://flagr:18000"),
4
5 // Habilita webhook server (já inicia automaticamente!)
6 vexilla.WithWebhookInvalidation(vexilla.WebhookConfig{
7 Port: 18001,
8 Secret: "shared-secret-with-flagr", // HMAC-SHA256 pra segurança
9 }),
10
11 // Polling como fallback (caso webhook falhe)
12 vexilla.WithRefreshInterval(5 * time.Minute),
13)
14
15client.Start(ctx)No Flagr, configure o webhook:
- Vá em Settings → Webhooks
- Adicione:
http://seu-servico:18001/webhook - Secret:
shared-secret-with-flagr(mesmo do código) - Events:
flag.updated,flag.deleted,flag.enabled,flag.disabled
Como funciona o webhook:
Performance:
- Polling tradicional: 5 minutos de latência
- Webhook: menos de 1 segundo de latência
- Speedup: 300x mais rápido!
Segurança: O webhook usa HMAC-SHA256 pra validar que a request realmente veio do Flagr:
1// Vexilla valida automaticamente
2signature := r.Header.Get("X-Flagr-Signature")
3expectedMAC := hmac.New(sha256.New, []byte(secret))
4expectedMAC.Write(payload)
5if !hmac.Equal(signature, expectedMAC.Sum(nil)) {
6 return errors.New("invalid signature")
7}Isso previne que alguém malicioso invalide seu cache sem autorização.
Admin API pra operações
Agora o Vexilla tem uma Admin API REST completa pra gerenciar o cache em runtime. Configuração super simples:
1client, _ := vexilla.New(
2 vexilla.WithFlagrEndpoint("http://flagr:18000"),
3
4 // Habilita Admin API
5 vexilla.WithAdminServer(vexilla.AdminConfig{
6 Port: 19000,
7 Enabled: true,
8 }),
9)
10
11client.Start(ctx)Endpoints disponíveis:
1# Health check (pra load balancer/k8s probes)
2GET /health
3Response: {"status": "healthy", "timestamp": "2025-12-21T10:30:00Z"}
4
5# Métricas do cache (Prometheus-friendly)
6GET /admin/stats
7Response: {
8 "storage": {
9 "keys_added": 1523,
10 "keys_updated": 342,
11 "keys_evicted": 12,
12 "hit_ratio": 0.987
13 },
14 "cache": {
15 "total_flags": 150,
16 "local_flags": 142,
17 "remote_flags": 8
18 },
19 "circuit": {
20 "state": "closed",
21 "consecutive_fails": 0
22 }
23}
24
25# Invalida flag específica (força re-fetch do Flagr)
26POST /admin/invalidate
27Body: {"flag_key": "new-checkout-flow"}
28Response: {"invalidated": ["new-checkout-flow"]}
29
30# Limpa todo o cache (cuidado em produção!)
31POST /admin/invalidate-all
32Response: {"invalidated": 150, "cache_cleared": true}
33
34# Força refresh de todas as flags
35POST /admin/refresh
36Response: {"refreshed": 150, "errors": 0}Casos de uso reais:
1# 1. Debugging: forçar refresh de flag específica
2curl -X POST http://localhost:19000/admin/invalidate \
3 -H "Content-Type: application/json" \
4 -d '{"flag_key": "problematic-flag"}'
5
6# 2. Monitoramento: expor métricas pro Prometheus
7# (scrape endpoint: http://vexilla:19000/admin/stats)
8
9# 3. Incident response: limpar cache durante problema
10curl -X POST http://localhost:19000/admin/invalidate-all
11
12# 4. Health check no Kubernetes
13livenessProbe:
14 httpGet:
15 path: /health
16 port: 19000
17 initialDelaySeconds: 5
18 periodSeconds: 10Segurança: A Admin API roda em porta separada (não expor publicamente!). Em produção, recomendo:
- Rodá-la apenas em rede interna
- Usar autenticação via reverse proxy (nginx/Envoy)
- Restringir IP source via firewall
HTTP Middleware pra integração simplificada
Se você tá usando HTTP handlers, agora tem um middleware pronto que injeta o cliente Vexilla no contexto da request:
1import (
2 "net/http"
3 "github.com/OrlandoBitencourt/vexilla"
4)
5
6func main() {
7 client, _ := vexilla.New(
8 vexilla.WithFlagrEndpoint("http://flagr:18000"),
9 )
10 client.Start(context.Background())
11
12 // Wrap seu handler com o middleware
13 handler := client.HTTPMiddleware(http.HandlerFunc(myHandler))
14
15 http.ListenAndServe(":8080", handler)
16}
17
18func myHandler(w http.ResponseWriter, r *http.Request) {
19 // Cliente já tá no contexto!
20 userID := r.Header.Get("X-User-ID")
21 country := r.Header.Get("X-Country")
22
23 evalCtx := vexilla.NewContext(userID).
24 WithAttribute("country", country)
25
26 // Pega o cliente do contexto
27 client := vexilla.FromContext(r.Context())
28
29 if client.Bool(r.Context(), "new-ui", evalCtx) {
30 renderNewUI(w)
31 } else {
32 renderOldUI(w)
33 }
34}Benefícios:
- Zero boilerplate pra passar o client por toda a stack
- Contexto HTTP já vem com trace IDs (OpenTelemetry integration)
- Fácil de testar (mock o context em testes)
Exemplo com framework popular (Chi Router):
1import "github.com/go-chi/chi/v5"
2
3r := chi.NewRouter()
4
5// Middleware global
6r.Use(client.HTTPMiddleware)
7
8r.Get("/api/products", func(w http.ResponseWriter, r *http.Request) {
9 client := vexilla.FromContext(r.Context())
10
11 // Extrai atributos da request
12 tier := r.URL.Query().Get("tier")
13 evalCtx := vexilla.NewContext("anonymous").
14 WithAttribute("tier", tier)
15
16 showPremiumFeatures := client.Bool(r.Context(), "premium-products", evalCtx)
17
18 products := fetchProducts(showPremiumFeatures)
19 json.NewEncoder(w).Encode(products)
20})Isso elimina a necessidade de dependency injection manual e deixa o código muito mais limpo!
Depois de ver tudo isso - arquitetura, performance, casos de uso - a pergunta que fica é: quando realmente vale a pena usar feature flags? Nem tudo precisa de flag, e adicionar flags desnecessárias só aumenta complexidade.
Quando usar feature flags?
Use quando:
- Tá lançando uma feature grande que pode dar problema
- Quer fazer gradual rollout (5% → 25% → 50% → 100%)
- Tem integrações externas que podem falhar
- Product quer fazer A/B testing
- Precisa de um kill switch de emergência
Não use quando:
- A feature é pequena e de baixo risco
- Você nunca vai precisar desligar ela
- Adiciona complexidade sem benefício
O que eu faria diferente se começasse hoje
- Começaria usando flags desde o dia 1 - Não é "overhead desnecessário", é seguro de vida
- Pensaria em performance desde cedo - Chamadas HTTP pra avaliar flags escalam mal
- Definiria processo de limpeza desde o início - Technical debt de flags esquecidas é real
- Documentaria as decisões de arquitetura - Por que essa flag existe? Quando remover?
- Treinaria o time todo - Não é só ferramenta de dev, é ferramenta de negócio
Armadilhas comuns (e como evitar)
Depois de 5 anos, já vi (e cometi) vários erros. Aqui vão os principais:
Flag debt (dívida de flags)
O erro: Criar flags e nunca remover. Eventualmente você tem 200 flags no código e ninguém sabe qual faz o quê.
A solução:
- Todo PR que adiciona flag deve ter um plano/data de expiração
- Code review obrigatório quando uma flag completa 100% rollout
- Remover a flag é parte da definição de "done" da feature (ou pelo menos deveria ser)
Flags aninhadas profundamente
O erro:
1if client.Bool("feature-a") {
2 if client.Bool("feature-b") {
3 if client.Bool("feature-c") {
4 // 😱 Impossível de testar todas as combinações
5 }
6 }
7}A solução: Se você precisa de 3+ níveis, provavelmente tá errado. Considere:
- Feature flags compostas (uma flag controla múltiplas sub-features)
- Refatorar a arquitetura da feature
- Usar strategies/adapters ao invés de ifs aninhados
Isso parece loucura, mas pode acontecer, e normalmente é uma necessidade de negocio, por exemplo imagina que voce precisa de um "disjuntor" pra desligar a feature nova como um todo, mas dentro da experiencia nova voce ainda pode ter variacoes com rollouts menores para saber o que da mais resultado, na pratica voce vai ter 2 feature flags pra isso funcionar.
Não testar o "fallback path"
O erro: Adicionar flag, testar só o caminho "enabled", nunca testar "disabled".
A solução:
1// Testa AMBOS os caminhos
2func TestNewFeature(t *testing.T) {
3 t.Run("feature enabled", func(t *testing.T) {
4 // mock flag = true
5 // testa comportamento novo
6 })
7
8 t.Run("feature disabled", func(t *testing.T) {
9 // mock flag = false
10 // testa que fallback funciona
11 })
12}Próximos Passos
E se ainda não usa feature flags no seu projeto, sério: comece. Sua sexta-feira às 18h vai agradecer.
Quer experimentar o Vexilla?
1. Rode a Demo Completa (5 minutos):
A melhor forma de entender o Vexilla é vendo funcionando. Rode a aplicação full-stack:
1# Clone o repo
2git clone https://github.com/OrlandoBitencourt/vexilla
3cd vexilla/examples/99-complete-api
4
5# Start Flagr
6docker run -d --name flagr -p 18000:18000 ghcr.io/openflagr/flagr
7
8# Setup flags
9cd .. && go run setup-flags.go && cd 99-complete-api
10
11# Terminal 1: Backend
12cd backend && go run main.go
13
14# Terminal 2: Frontend
15cd frontend && npm install && npm run dev
16
17# Abra: http://localhost:3000O que você vai ver:
- Interface interativa mostrando rollout determinístico
- Kill switches em ação (2 segundos pra rollback!)
- Simulador com 5 usuários diferentes
- Admin panel com métricas em tempo real
- Checkout V1 vs V2 lado a lado
2. Explore os outros 10 exemplos práticos:
- 01-basic-usage - Começar do zero
- 03-deterministic-rollout - Rollouts 100% offline com buckets
- 04-webhook-invalidation - Atualizações em tempo real
- 06-http-middleware - Integração com servidores HTTP
- 09-telemetry - Métricas e observabilidade
3. Leia a arquitetura completa:
ARCHITECTURE.md - decisões técnicas documentadas em detalhes
4. Contribua ou reporte issues:
github.com/OrlandoBitencourt/vexilla
5. Dúvidas?
Me chama no X (@orlandocbit) ou abre uma issue no GitHub.
Referência Rápida
Números-chave que você viu neste artigo:
- 335ns: Latência de avaliação local (simple eval)
- 37.7M ops/s: Throughput máximo (concurrent eval)
- 200x-447.000x: Speedup vs Flagr direto (dependendo do cenário)
- 97%: Redução de uso de memória com filtragem
- 95%: Proporção típica de flags locais vs remotas
- Menos de 1s: Propagação de mudanças via webhook
Links úteis:
- Repositório: github.com/OrlandoBitencourt/vexilla
- Documentação: pkg.go.dev/github.com/OrlandoBitencourt/vexilla
- Exemplos: github.com/OrlandoBitencourt/vexilla/tree/main/examples
- Benchmarks: benchmarks/results/REAL_RESULTS.md
- Package: pkg.go.dev/github.com/OrlandoBitencourt/vexilla
Tem alguma história ou dor com feature flags? Me conta no X!

