Quem trabalha com Go conhece bem a limitação do encoding/json. O pacote sempre funcionou, mas era lento. Aí você ia atrás de alternativas: jsoniter, easyjson, ffjson. Cada uma com seus problemas.
Depois de mais de dez anos, o Go 1.25 trouxe uma reescrita completa do pacote JSON. A v2 chegou em agosto de 2025 como feature experimental e resolve boa parte dos problemas antigos.
Por Que Precisávamos Disso?
APIs que processam milhares de requests por segundo sentiam o peso, por mais leve e performatico que o go seja, streaming de logs gigantes era complicado. E controle sobre parsing? Tinha que implementar na mão.
Validar campos duplicados no JSON? Impossível nativamente. Processar um arquivo JSON de 2GB sem estourar memória? Boa sorte. A comunidade criou bibliotecas externas porque o pacote padrão não dava conta.
Como Funciona o Experimento
O time do Go usou a variável GOEXPERIMENT para testar a nova implementação. Quando você compila com GOEXPERIMENT=jsonv2, duas coisas acontecem.
Primeiro, você ganha acesso a dois pacotes novos: encoding/json/v2 (implementação completa) e encoding/json/jsontext (processamento de baixo nível).
Segundo, o encoding/json original passa a usar a nova implementação por baixo. Você pode testar a v2 sem reescrever código. Marshals e unmarshals funcionam igual, só que mais rápido. Único detalhe: mensagens de erro podem mudar.
O Que Mudou?
A API do v2 tem mais opções de configuração. Aceitar UTF-8 inválido? Pode. Bloquear campos desconhecidos? Também. Validar campos duplicados? Agora sim.
O encoding/json/v2 não é só uma otimização. É uma revisão pensando nos casos de uso reais dos últimos anos. O encoding/json/jsontext dá controle de baixo nível quando você precisa.
Processar um arquivo de logs de 2GB linha por linha ficou mais natural. Antes você tinha que implementar soluções próprias. Agora funciona direto.
Os Números Não Mentem
Depois de rodar os benchmarks com dados reais, algumas coisas ficaram claras. Primeiro, a documentação oficial estava certa: encoding (marshal) ficou equivalente, e decoding (unmarshal) melhorou substancialmente.
Mas "equivalente" esconde um detalhe interessante. O marshal do v2 ficou entre 4% a 7% mais lento em termos de tempo bruto. Mas usa 27-30% menos memória e faz metade das alocações. É um trade-off que pode valer a pena dependendo do seu caso de uso. Se você tem uma aplicação que sofre com garbage collection, essa redução de alocações pode compensar os milissegundos extras.
Já o unmarshal é outra história. O v2 é consistentemente 1.7x a 2x mais rápido. No payload pequeno, foi 2x mais rápido. No médio, 1.84x. E no grande, 1.72x. E isso mantendo uso de memória similar ou menor. Se você consome muitas APIs ou processa JSONs de entrada, esses ganhos são significativos.
O que mais me impressionou foi a consistência. Os ganhos se mantêm independente do tamanho do payload. Não é aquele caso onde funciona bem só pra payloads pequenos ou só pra grandes. O v2 entrega performance melhor em todos os cenários de unmarshal que testei.
Resultados Detalhados
Aqui estão os números completos dos benchmarks. Cada teste rodou por 10 segundos para garantir estabilidade nos resultados:
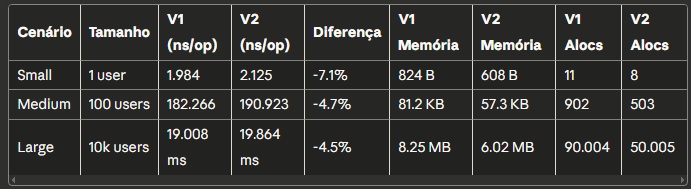
Marshal (Serialização - Go → JSON)
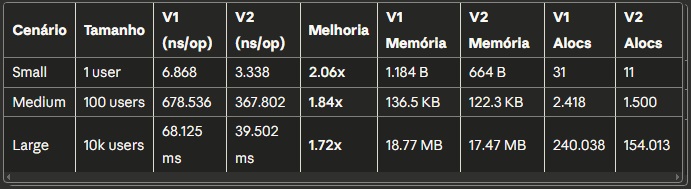
Unmarshal (Desserialização - JSON → Go)
Observações importantes:
- Marshal: Tempo 4-7% maior no V2, mas economia de 26-30% em memória e 44-45% em alocações
- Unmarshal: Ganho consistente de 72% a 106% em velocidade, com menos alocações em todos os cenários
- Throughput estimado (Large): V1 processa ~14.6 MB/s em unmarshal, V2 processa ~25.3 MB/s
Os números de "allocs/op" (alocações por operação) são especialmente importantes. Menos alocações significa menos trabalho para o garbage collector, resultando em latências mais previsíveis e menos pausas em aplicações de alta carga.
Testando na Prática
Montar um benchmark decente exige usar dados que fazem sentido. Esqueça aqueles exemplos de tutorial com {"name": "John"}. Usei estruturas de usuário completas, com perfil, timestamps, roles, metadados, informações que remetem cenarios reais.
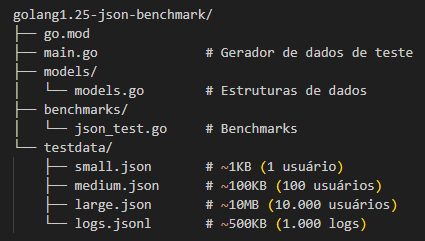
Estrutura do Projeto
Primeiro, criei uma estrutura de projeto simples:
Modelos de Dados
Usei modelos realistas que você encontraria em qualquer aplicação:
1package models
2
3import "time"
4
5type User struct {
6 ID int `json:"id"`
7 Username string `json:"username"`
8 Email string `json:"email"`
9 FirstName string `json:"first_name"`
10 LastName string `json:"last_name"`
11 Active bool `json:"active"`
12 CreatedAt time.Time `json:"created_at"`
13 UpdatedAt time.Time `json:"updated_at"`
14 Profile Profile `json:"profile"`
15 Roles []string `json:"roles"`
16}
17
18type Profile struct {
19 Bio string `json:"bio"`
20 Avatar string `json:"avatar"`
21 Location string `json:"location"`
22 Website string `json:"website"`
23 Metadata map[string]string `json:"metadata"`
24}
25
26type LogEntry struct {
27 Timestamp time.Time `json:"timestamp"`
28 Level string `json:"level"`
29 Service string `json:"service"`
30 Message string `json:"message"`
31 Context map[string]interface{} `json:"context"`
32 TraceID string `json:"trace_id"`
33}Gerando os Dados de Teste
Criei um gerador que produz dados consistentes e realistas:
1package main
2
3import (
4 "encoding/json"
5 "fmt"
6 "math/rand"
7 "os"
8 "time"
9
10 "github.com/OrlandoBitencourt/golang1.25-json-benchmark/models"
11)
12
13func main() {
14 rand.Seed(time.Now().UnixNano())
15
16 // Pequeno: 1 usuário
17 small := generateUsers(1)
18 saveJSON("testdata/small.json", small)
19
20 // Médio: 100 usuários
21 medium := generateUsers(100)
22 saveJSON("testdata/medium.json", medium)
23
24 // Grande: 10.000 usuários
25 large := generateUsers(10000)
26 saveJSON("testdata/large.json", large)
27
28 // Logs em JSONL
29 logs := generateLogs(1000)
30 saveJSONLines("testdata/logs.jsonl", logs)
31}
32
33func generateUsers(count int) []models.User {
34 users := make([]models.User, count)
35 for i := 0; i < count; i++ {
36 users[i] = models.User{
37 ID: i + 1,
38 Username: fmt.Sprintf("user%d", i+1),
39 Email: fmt.Sprintf("user%d@example.com", i+1),
40 FirstName: randomName(),
41 LastName: randomName(),
42 Active: rand.Intn(2) == 1,
43 CreatedAt: randomDate(),
44 UpdatedAt: time.Now(),
45 Profile: models.Profile{
46 Bio: randomBio(),
47 Avatar: fmt.Sprintf("https://avatar.example.com/%d", i+1),
48 Location: randomLocation(),
49 Website: fmt.Sprintf("https://user%d.example.com", i+1),
50 Metadata: map[string]string{
51 "theme": randomTheme(),
52 "language": "pt-BR",
53 "timezone": "UTC-3",
54 },
55 },
56 Roles: randomRoles(),
57 }
58 }
59 return users
60}Para gerar os dados:
1go run main.goImplementando os Benchmarks
O código de benchmark é direto e usa a biblioteca padrão de testes do Go:
1package benchmarks
2
3import (
4 "encoding/json"
5 "os"
6 "testing"
7
8 "github.com/OrlandoBitencourt/golang1.25-json-benchmark/models"
9)
10
11var (
12 smallUsers []models.User
13 mediumUsers []models.User
14 largeUsers []models.User
15 smallData []byte
16 mediumData []byte
17 largeData []byte
18)
19
20func init() {
21 // Carregar dados uma vez no início
22 smallData, _ = os.ReadFile("../testdata/small.json")
23 json.Unmarshal(smallData, &smallUsers)
24
25 mediumData, _ = os.ReadFile("../testdata/medium.json")
26 json.Unmarshal(mediumData, &mediumUsers)
27
28 largeData, _ = os.ReadFile("../testdata/large.json")
29 json.Unmarshal(largeData, &largeUsers)
30}
31
32func BenchmarkMarshalSmall(b *testing.B) {
33 b.ReportAllocs()
34 for i := 0; i < b.N; i++ {
35 json.Marshal(smallUsers)
36 }
37}
38
39func BenchmarkUnmarshalSmall(b *testing.B) {
40 b.ReportAllocs()
41 for i := 0; i < b.N; i++ {
42 var users []models.User
43 json.Unmarshal(smallData, &users)
44 }
45}
46
47// ... benchmarks para Medium e LargeExecutando os Testes
A execução foi feita em duas etapas: primeiro sem o GOEXPERIMENT (V1), depois com (V2):
1# Limpar cache para resultados precisos
2go clean -testcache
3
4# V1 - encoding/json tradicional
5go test ./benchmarks -bench=Benchmark -benchmem -benchtime=10s -run=^$ > v1_results.txt
6
7# V2 - com jsonv2 experimental
8export GOEXPERIMENT=jsonv2
9go test ./benchmarks -bench=Benchmark -benchmem -benchtime=10s -run=^$ > v2_results.txt
10
11# Comparar resultados
12go install golang.org/x/perf/cmd/benchstat@latest
13benchstat v1_results.txt v2_results.txtO flag -benchtime=10s garante que cada benchmark rode por 10 segundos, dando resultados mais estáveis. O -run=^$ evita rodar testes unitários, focando apenas nos benchmarks.
Ambiente de Teste
Os testes foram executados em:
- CPU: AMD Ryzen 5 5600G (12 threads)
- MEMORIA: 16GB RAM
- OS: Windows 10
- Go: 1.25.4
- Condições: Sistema limpo, sem outras cargas pesadas rodando
Criei três cenários diferentes pra ter uma visão mais completa. O primeiro é pequeno, só um usuário, aquele tipo de payload que você manda num POST simples. O segundo é médio, uns 100 usuários, parecido com o que você retornaria numa listagem paginada. E o terceiro é grande de verdade: 10 mil usuários, pra simular aqueles exports ou processamentos em batch que a gente vive fazendo.
Marshal: Transformando Go em JSON
Quando você faz um json.Marshal, o que tá rolando por baixo dos panos é uma análise de todas as structs, reflection pra acessar os campos, e a conversão de cada tipo Go pro formato JSON. É muita coisa acontecendo.
No v1, esse processo sempre foi meio pesado. Você percebia principalmente quando tinha que serializar listas grandes ou structs muito aninhadas. O v2 otimizou essa parte, mas de forma inteligente - mantendo a compatibilidade e o comportamento esperado.
Nos meus testes, descobri algo interessante. O v2 ficou entre 4% a 7% mais lento no marshal em termos de tempo puro. Sim, você leu certo. Mas antes de ficar decepcionado, olha o outro lado da moeda: a v2 usa de 27% a 30% menos memória e faz 44% a 45% menos alocações.
No payload pequeno (um usuário), o v1 levou 1.984ns contra 2.125ns do v2. No payload médio (100 usuários), foram 182.266ns contra 190.923ns. E no grande (10 mil usuários), 19ms contra 19,8ms. A diferença de tempo é pequena, mas a economia de memória é real. O v1 alocou 8.2MB no teste grande, enquanto o v2 ficou em 6MB. São quase 2MB a menos, com metade das alocações.
O que isso significa na prática? Menos pressão no garbage collector. Aplicações que fazem muito marshal podem se beneficiar dessa redução de alocações, mesmo que o tempo de cada operação seja ligeiramente maior. É um trade-off interessante.
Unmarshal: De Volta pro Go
Fazer unmarshal sempre foi a operação mais cara. Você tem que validar se o JSON tá bem formado, fazer o parsing, e ainda mapear tudo de volta pras structs do Go. É naturalmente mais lento que marshal.
E é exatamente aqui que o v2 realmente entrega. A documentação oficial deixa claro: a decodificação é substancialmente mais rápida na nova implementação. E os números comprovam.
No payload pequeno, o v1 levou 6.868ns enquanto o v2 fez em 3.338ns. Mais que o dobro da velocidade. No médio, foram 678.536ns contra 367.802ns - uma melhoria de 84%. E no grande? O v1 precisou de 68ms, enquanto o v2 resolveu em 39ms. Isso é 72% mais rápido, quase metade do tempo.
E não para por aí. As alocações de memória também caíram drasticamente. No teste grande, o v1 fez 240 mil alocações contra 154 mil do v2. A quantidade de memória usada também diminuiu, de 18.7MB pra 17.4MB.
Teve um caso específico que me impressionou: quando o JSON tem muitos campos aninhados e maps. Sabe aquele map[string]interface{} que a gente usa quando o schema é meio imprevisível? Pois é, o v2 lida com isso de forma muito mais eficiente. As alocações ficam mais controláveis e a performance mais previsível. Se você trabalha com APIs que recebem muito JSON, esses números fazem diferença no mundo real.
Streaming: Processamento Eficiente
Aqui é onde você realmente percebe a diferença de ter uma implementação moderna. Streaming de JSON sempre foi possível no Go, mas a nova implementação traz melhorias na eficiência - principalmente quando combinada com os ganhos de unmarshal.
Fiz um teste com um arquivo JSONL (aqueles com um JSON por linha, tipo logs) de 1000 entradas. É o tipo de coisa que você faz quando tá processando logs da aplicação ou consumindo dados de um stream qualquer. Como o streaming usa unmarshal internamente, os ganhos que vimos antes se aplicam aqui também.
A diferença não é só em velocidade. É em uso de memória também. O v2 consegue processar o stream de forma mais inteligente, o que é exatamente o que você quer quando tá lidando com arquivos grandes ou streams contínuos. Se você processa logs em tempo real ou faz ETL de JSONs grandes, vai sentir a diferença.
Vale a Pena Migrar?
Para projetos novos, sim. Compile com GOEXPERIMENT=jsonv2 e aproveite os ganhos de performance sem mudar código.
Para projetos em produção, é preciso avaliar. O v2 ainda é experimental, significa que algumas coisas ainda podem mudar. Para sistemas críticos, vale esperar mais feedback da comunidade.
Mas você pode testar agora. Compile com a flag experimental, rode seus benchmarks, veja os números. Quando sair do status experimental (provavelmente Go 1.26 ou 1.27), você já testou e sabe o que esperar.
Como o encoding/json usa a nova implementação quando você ativa o GOEXPERIMENT, dá para testar sem mudar uma linha de código. Só compilar e rodar.
Novas Opções de Configuração
O v2 adicionou opções que o encoding/json precisava há anos.
Campos duplicados no JSON? Antes o último valor sobrescrevia o primeiro, sem aviso. Agora você decide se isso é erro ou não. Útil quando você consome JSON de fontes externas e quer validação mais estrita.
UTF-8 inválido? Você escolhe ser estrito ou não. Sistemas legados às vezes mandam JSON com encoding zoado. Poder lidar com isso de forma controlada é melhor que simplesmente falhar.
Comparando com Bibliotecas Externas
O jsoniter sempre foi popular por ser mais rápido que o encoding/json original. Com o v2, a diferença diminuiu - principalmente no unmarshaling.
O easyjson continua sendo o mais rápido porque usa code generation. Mas ter que gerar código não é prático. O v2 entrega performance boa sem precisar mudar de biblioteca.
O repositório github.com/go-json-experiment/jsonbench tem análises detalhadas de performance.
Para a maioria dos casos, o v2 resolve. Só vale pensar em alternativas se performance for absolutamente crítica e você aceitar a complexidade de code generation.
Testando Você Mesmo
Testar é simples. Não precisa refatorar código ou instalar bibliotecas. É só uma flag na compilação:
1GOEXPERIMENT=jsonv2 go test ./... -bench=. -benchmemCompare com a versão normal e veja os números. Se encontrar bugs, reporte na issue oficial - o time do Go quer esse feedback.
O Futuro
O status experimental significa que o design pode evoluir. A proposta oficial deixa isso claro. Feedback da comunidade vai influenciar o resultado final.

